Overview
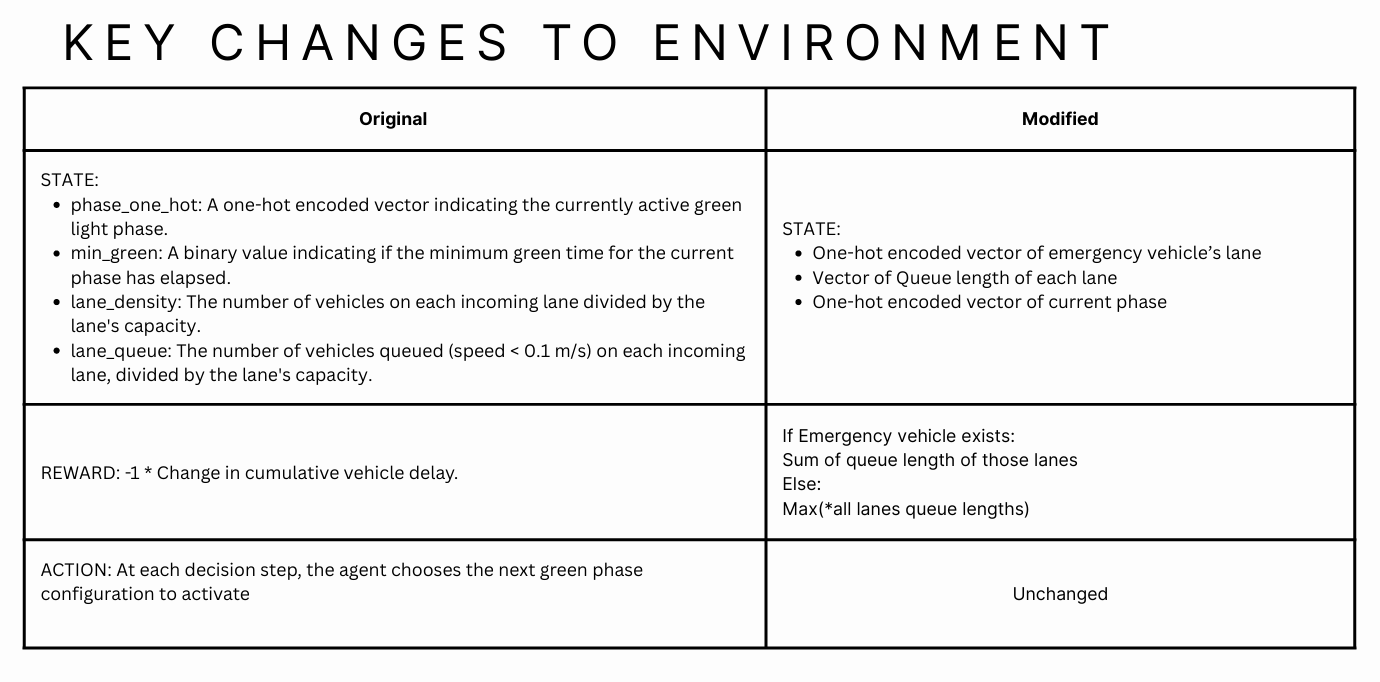
The main idea is to reduce the overall wait time for emergency vehicles traveling from one destination to another. To achieve this task, we used Reinforcement Learning to train a traffic signal controller in a simulated environment (SUMO-RL). We trained the agent with various algorithms (SARSA, Q-Learning, DQN, Double DQN, and A2C) and compared their performance.
Algorithm Comparison
Fixed TL Results
The traffic light follows a static program with a fixed cycle: 42 seconds green for one direction (likely North-South based on connections), 2 seconds yellow, 42 seconds green for the other direction, and 2 seconds yellow.
SARSA Results
- Since the max queue length for the environment = 20, the state space can get really big. To address this, we quantized the queue length vector into 4 regions:
[0-5 (Low 1), 5-10 (Low 2), 10-15 (High 1), 15-20 (High 2)]. - Phase and Emergency vehicle lane was also changed to cardinal numbers.
- The new state space size became
[0-3, 0-3, 0-3, 0-3, 0-3, 0-4] = 5120. - Trained for 200 episodes with epsilon decay and discount factor of 0.99.
Q-Learning Results
- Followed a similar state space design as SARSA.
- The agent was trained for 100 episodes with epsilon decay and a discount factor of 0.9.
DQN Results
- Observation: Normalized queue lengths of each lane + one-hot-encoded phases + emergency vehicles boolean value (0 or 1).
- Action: 0 to stay in current phase, 1 to go to the next phase.
- Reward:
-1 * max(n_t, w_t)or sum of queue lengths where emergency vehicles exist. - Buffer size: 500 | Batch size: 32
- Episodes: 200 | Learning Rate: 0.01
- Discount factor: 0.99
- Network: 3 layers with 128 neurons, 12 input size, 2 output.
Double DQN (DDQN) Results
- Observation: Normalized queue lengths of each lane + one-hot-encoded phases + emergency vehicles boolean value (0 or 1).
- Action: 0 to stay in current phase, 1 to go to the next phase.
- Reward:
-1 * max(n_t, w_t)or sum of queue lengths where emergency vehicles exist. - Buffer size: 500 | Batch size: 32
- Episodes: 200 | Learning Rate: 0.01
- Discount factor: 0.99
- Network: 3 layers with 128 neurons, 12 input size, 2 output.
Key Observations
Reward Shaping
Reward shaping was key. Only using the summation of queue length was not enough; the model began gaming the rewards by minimizing length for one lane while keeping the other lane full.
Phase Simplification
Simplifying phases helped significantly. Granular control on phases led to higher convergence times, and often it is unrealistic to keep only one lane open at a time.
Episode Lengths
We trained the model on shorter episode lengths to emphasize quicker model updates and then tested it on longer episodes. This showed us the fastest convergence.
Reward Hacking in Action
Notice how the model learns to minimize the penalty by letting 1 lane wait indefinitely while keeping the other open.